在高级语言程序设计中,我们不仅要求程序能够顺序执行,还要求其能够执行不同分支,或者重复执行某些操作。在汇编语言中,同样具有相同的能力,可以由相应的指令来控制程序的执行流程。因为毕竟高级语言都是汇编实现的,只是不直观而已。
转移
无条件转移为JMP,类似c语言中的 goto。在c语言中,goto是不推荐使用的,会使程序难以控制和理解,但在汇编中,没有相应的if 和 while语句,只能使用 JMP来完成逻辑复杂的控制结构。
JMP分为段内转移和段间转移,不过在windows编程上,一个代码段的大小为 4GB,一般不需要段间转移。
条件转移是由CPU提供多个标志位,在执行这类指令之前,检查之前已经设置的标志位的状态来决定是否进行转移。可以想象,通过条件转移,可以实现分支和循环。
分支
在汇编中,设计一个分支结构的思路基本是这样的,由条件转移指令来判断条件是否满足,若满足,则跳过分支程序,否则继续向下执行,最后会合。
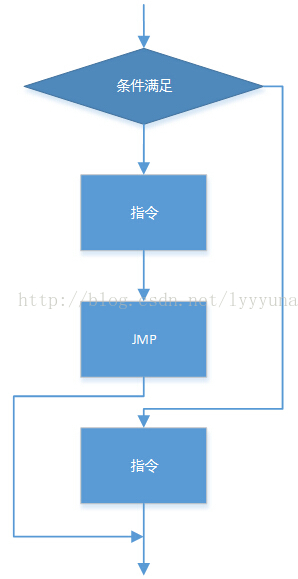
求 x的符号
原c 程序
- </pre><pre name=“code” class=“cpp”>int x = 10;
- int signX;
- int main()
- {
- if (x > 0)
- signX = 1;
- else if (x == 0)
- signX = 0;
- else
- signX = -1;
- }
对应的汇编
- x SDWORD -45
- signX SDWORD ?
- mov signX, 0
- cmp x, 0
- jz a70 ;为0
- jg a60 ;大于0
- mov signX, -1
- jmp a70
- a60:
- mov signX, 1
- a70:
二分查找
对于一个已排序的数组,最快的查找一个元素的方法不是顺序查找,而是二分查找。这个用c 语言写非常方便。首先我们还是画出流程图,这有助于我们用 JMP转换之。
数组为R,元素个数为n,要查找的数为a。
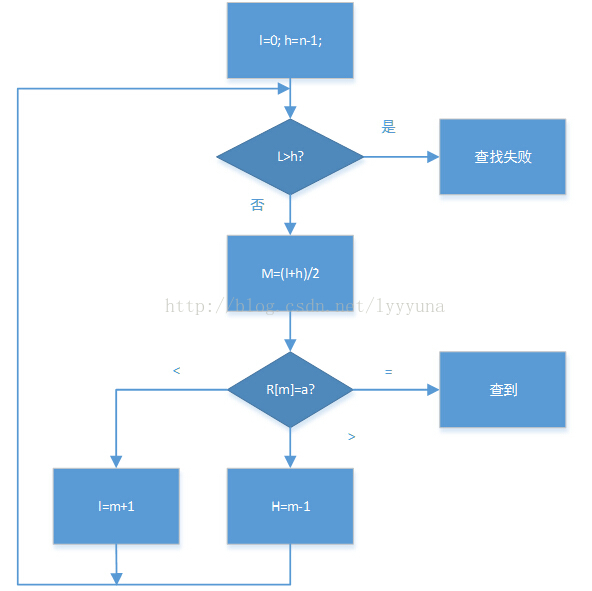
执行过程为:
(1)先设定查找范围为下界 l到上界h
(2)如果下界大于上界,且没查到,则查找失败
(3)取下界和上界的中点m=(l+h)/2,该数为R[m]
(4)若该数为a,则算法结束
(5)若该数小于a,则修改下界l=m+1,并跳转到第二步
(6)若该数大于a,则修改上界 h=m-1,并跳转到第二步
汇编源码
- .386
- .model flat,stdcall
- optioncasemap:none
- includelib msvcrt.lib
- printf PROTO C :dword, :vararg
- .data
- dArray dword 50, 56, 64, 73, 83, 92, 103, 105
- ITEMS equ $-dArray)/4 ; 数组长度
- Index dword ?
- Count dword ?
- szFmt byte ‘Index=%d Count=%d Element=%d’, 0; 格式化字符串
- szErr byte ‘Not Found’
- l sdword ?
- h sdword ?
- m sdword ?
- a sdword 83 ; 所查找的数字
- .code
- start:
- mov Index, -1;
- mov Count, 0
- mov l, 0
- mov h, ITEMS-1;
- mov ecx, l
- mov edx, h
- b10:
- cmp ecx, edx ; 下界和上界比较
- jg b40 ; 超出,则未找到
- mov esi, ecx;
- add esi, edx
- shr esi, 1 ; m = (l+h)>>1
- inc Count
- mov eax, a ; 取出被比较的数
- cmp eax, dArray[esi*4] ; 取出该数
- jz b30 ; 相等
- jg b20 ; 比 a 小,修改下界
- ; 比 a 大,修改上界
- mov edx, esi
- dec edx ; h = m-1
- jmp b10
- b20:
- mov ecx, esi
- inc ecx ; l = m+1
- jmp b10
- b30:
- mov Index, esi
- ; 调用 c 库的 printf
- invoke printf, offset szFmt, Index, Count, dArray[esi*4]
- jmp b50
- b40:
- ; 查找失败
- invoke printf, offset szErr
- b50:
- ret
- end start
有序表插入
首先遍历数组,找到m,满足 R[m-1]<a && R[m]>a。然后将R[m..n-1]每一个元素向后移动一个位置,再插入a。
关键部分汇编代码
- start:
- mov eax, Element ; 将插入的元素
- mov esi, 0 ; 当前比较元素的下标
- c10:
- cmp dArray[esi*4], eax
- ja c20
- inc esi
- cmp esi, ITEMS ; 超出数组长度,
- jb c10 ; 没有超出
- ;
- c20:
- mov edi, ITEMS-1 ; 从数组尾部开始移动
- c30:
- cmp edi, esi ; 与插入位置比较
- jl c40 ; 移动完成
- ; 还没完成,继续移动
- mov ebx, dArray[edi*4]
- mov dArray[edi*4+4], ebx ; 向后移动一个元素
- dec edi
- jmp c30 ; 继续判断,决定是否移动
- c40:
- mov dArray[esi*4], eax ; 移动完成,插入元素
循环
实际编码解决问题时,经常遇到大量重复的动作,利用循环结构可以简化程序的编写。实际在上文中,已经有循环部分出现,但那是不定次数的循环。
一个循环结构分为三部分:循环初始化,循环体,循环结束控制。
一个固定次数的循环,有LOOP命令来实现,循环次数在ECX中。
阶乘
这里直接使用ECX 作为乘数,其会随循环递减,正好符合阶乘的定义。
- .data
- Fact dword ?
- N EQU 5
- .code
- start:
- mov ecx, N ; 循环初值,同时也是乘数初值
- mov eax, 1 ; fact 初值
- e10:
- imul eax, ecx ; 相乘
- loop e10
- mov Fact, eax ; 阶乘结果
冒泡
冒泡算法是一个多重循环。
- start:
- mov ecx, ITEMS-1
- i10:
- xor esi, esi ; 清零
- i20:
- mov eax, dArray[esi*4]
- mov ebx, dArray[esi*4+4]
- cmp eax, ebx ; 比较相邻的两个数
- jl i30
- mov dArray[esi*4], ebx ;较大的数在左边,需要移动
- mov dArray[esi*4+4], eax ; 需要交换两个数
- ; 比较下一对数
- i30:
- inc esi
- cmp esi, ecx
- jb i20 ; 内循环,一遍下来,最大的数,移到了最右边
- loop i10 ; 外循环
参考文献
[1] 谭毓安, 张雪兰. Windows汇编语言程序设计教程. 北京: 电子工业出版社, 2005.